My last several posts have looked at how I’ve created digital essays through Twine (an online tool designed for writers of hypertext fiction). In this post, I’ll outline another affordance that I’ve recently made through this platform.
I spent the majority of 2018 studying for my oral exams at Stony Brook University. I read hundreds of texts, ranging from Victorian poems to queer experimental reading to algorithmic criticism, and realizing early on that I was going to have a hard time keeping track of all of my notes and, more importantly, remembering the connections I’d made between all of these texts. As a solution, I turned to Twine and its ability to organize non-linear connections as a way to build my own database for studying.
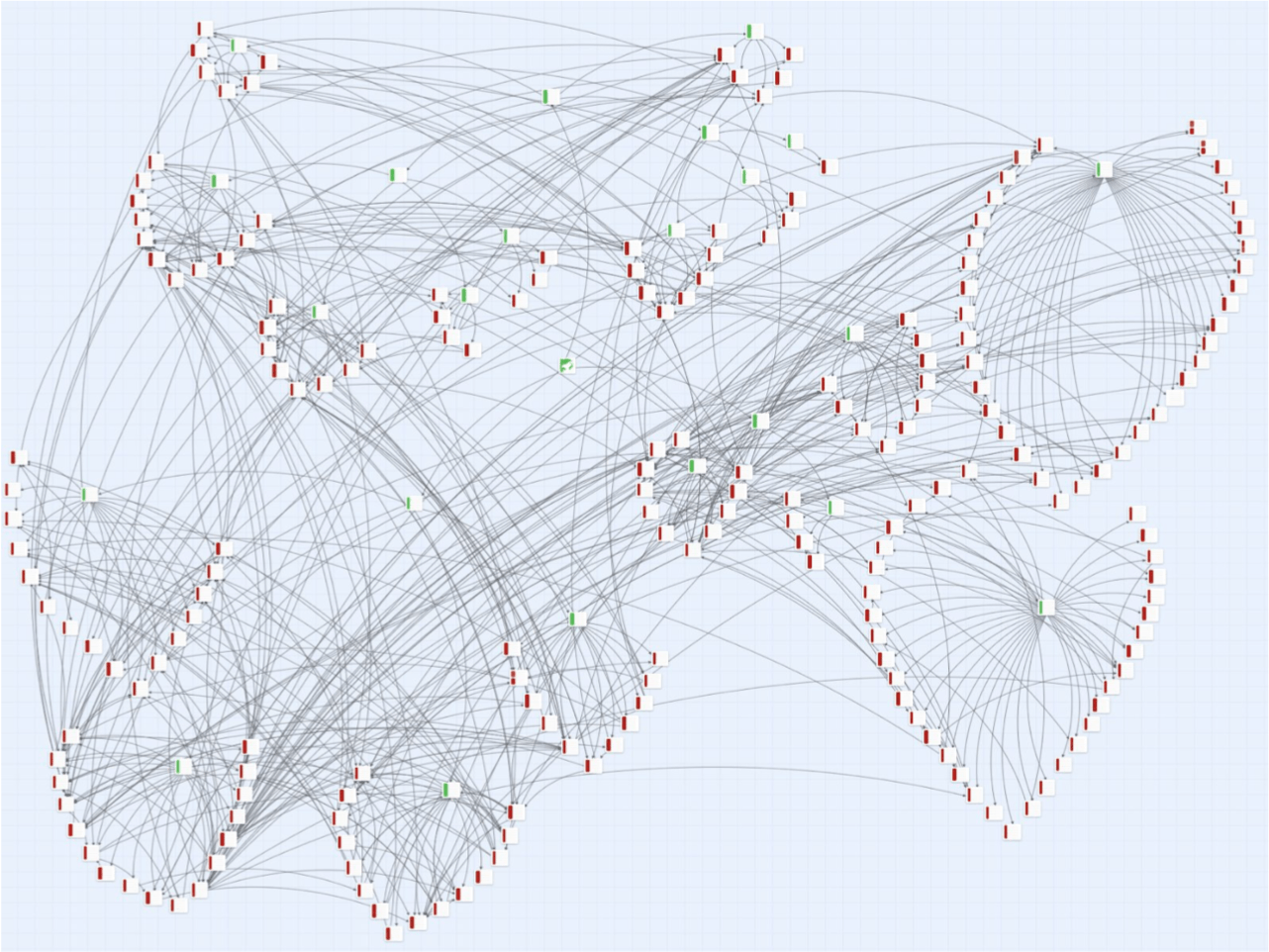
Image of the “database” I created on Twine. Each red-marked box represents a single text from my readings; green-marked boxes indicate categories around which I organized these readings (e.g. new media studies, data visualizations, etc.); black lines mark references I made from one text to another.
As seen in the image above, the connections I made between were many. Twine served as useful platform by storing, displaying, and assisting in the recall of these ideas. As a strongly visual learner, having this bird’s-eye-view of my own connections was also incredibly helpful.
My own understanding of how a database like this one might work was, conveniently, aided by many of the readings for the exams. In The Language of New Media, Lev Manovich identifies two primary ways in which we organize data: narratives and databases.1 While narratives are useful for telling a chronological story, databases are better for making rhizomatic, nonhierarchical connections. Expanding on Manovich’s categories, N. Katherine Hayles explains that the relationship between these two forms of organization are not competitive, but rather symbiotic: we explain databases through narratives; databases collect narratives.2 This is seen in my own Twine-database example in that the database helped me to organize my thoughts and the many stories I read, and in the end, this organization allowed me a clear method of accessing those thoughts and stories, proliferating the number of narratives that I might make from the ensuing connections.
In addition to highly recommending this method of studying for anyone who might be in a similar boat, I’d like to note one more benefit of creating a database of your own work. In having a centralized location for these ideas, I was able to create a distance reading of my own notes. This proved useful as, when I compiled my writing into a single document, using a feature on Twine to publish a file of everything I’d entered into my database, I found that I’d taken over 400 pages of double-spaced notes. From this document, I conducted a number of algorithmic readings that I then used to create my own data visualizations (another DH-tool-turned-study-aid).

A word cloud generated by my own notes for my oral exams.
Using Voyant to create a word cloud, I found more ways to think about the connections I’d made in my notes. For example, it was clear that I was most attuned to queer theory and queer methods of reading, as the term “queer” appeared more than any other term in the corpus of my own notes, tallying 214 mentions altogether. While this word cloud functions more as explication than exploration (it didn’t reveal anything all that new to me), I was surprised by how often I (over)used the term “offers.” Butler offers her definition here… Haraway offers the figure of the cyborg… Guess I need to work on being less repetitive in the way I discuss other scholars’ works. Oops.
Happy studies!
Leave a Reply